Leven at Newby Bridge using HBV model in eWaterCycle#
This notebook demonstrates how eWaterCycle is used to run a model. For the EuroCSDMS workshop we, of course, choose the beautiful region we are in as a case study. River discharge in river Leven is measured at the weirs at Newby Bridge, see the photo below. This observational data is available in the CamelsGB dataset (Coxon, 2020). The larger Caravan (collection of Camels…) dataset is available through eWaterCycle and will be used below.

Weirs on the River Leven at Newby Bridge by G Laird
As a model we choose the classic HBV model for its simplicity. This nicely demonstrates how eWaterCycle works. More complex models are available through eWaterCycle, however:
these often require parameter sets specific to a region
these are more computationally intensive to run and therefore unsuited for a short 45 minute workshop.
Ask us about available models if you want to collaborate!
HBV model structure#
The stucture of the HBV model is shown below. Do note that the figure is missing a snow reservoir, however this has been implemented in the HBV model in this notebook.
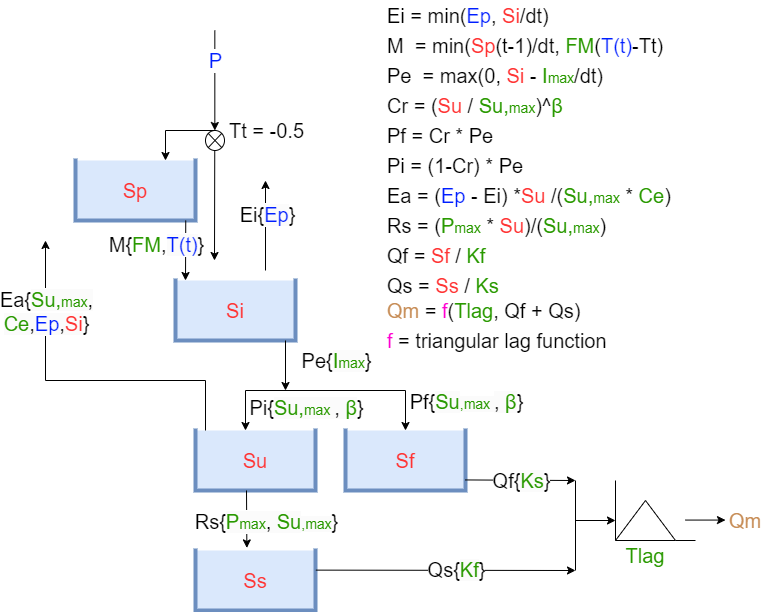
Image from the TU Delft course ENVM1502 - “River Basin Hydrology” by Markus Hrachowitz
Starting up#
To start up, we need to import eWaterCycle and a number of general Python libraries. ‘Under the hood’ eWaterCycle depends on a large number of other pieces of software, including but not limited to
grpc4bmi, a ‘translator’ for BMI function calls between different programming languages and across containers. This library was build by the eWaterCycle team, but is available openly for anyone that can benefit from its functionality.
apptainer, a container engine that runs the model-containers (Docker is supported too).
ESMValTool, a climate data processing toolbox that originally intended to post-process climate data from CMIP projects for inclusion in IPCC reports, we adopted as tool for pre-processing climate data into forcing data for hydrological models
Numerous hydrological models that are made available as plugins to eWaterCycle, see eWaterCycle-leakybucket as an example. Note that plugins do not have to be owned and maintained by the eWaterCycle team: anyone with a model can make a plugin for eWaterCycle and make their model be available for others through the platform.
Furthermore, eWaterCycle requires forcing data, obsrvational data and parameter sets to be available to users. If you want to install eWaterCycle on your own infrastructure, see the eWaterCycle documentation or contact us.
# general python
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
import numpy as np
from pathlib import Path
import pandas as pd
import matplotlib.pyplot as plt
import xarray as xr
#niceties
from rich import print
# general eWaterCycle
import ewatercycle
import ewatercycle.models
import ewatercycle.forcing
Choose region and time period:#
The HBV model is a lumped hydrological model. It considers a catchment as a homogenious area and calculates the major hydrological processes in it. It requires spatially aggregated rainfall and potential evaporation as inputs (ie. forcings). To calculate its modelled discharge at the outlet of the catchment it also needs a set of parameters. Usually these paramters are calibrated using (historical) observational data, so this is also required.
in eWaterCycle we provide access to the Caravan dataset, which contains all of the above data for all the catchments in the different Camels datasets. However, for two reasons, we don’t use the rainfall and potential evaporation data from Caravan
This allows us to demonstrate how to generate forcing data for any model from ERA5 (working on ERA5Land) and from CMIP data
There is a known problem with the caravan evaporation data and we want to avoid using it here.
We thus only use the Caravan dataset to retreive
a shapefile of the region of interest, to be used as input for generating the forcing from ERA5
the observational data of river discharge
Using the interactive maps at eWaterCycle caravan map one can easily retrieve the identifier of the catchment.
Note that changing the region below will work, but that the parameters that are loaded later in this notebook are calibrated specifically for this catchment!
camelsgb_id = "camelsgb_73010"
We have to specify start and end date of the experiment that we want to do. For now we don’t fuzz with diverences between calibration and validation periods (which officially of course is very bad…)
experiment_start_date = "1997-08-01T00:00:00Z"
experiment_end_date = "2000-08-31T00:00:00Z"
Set up paths#
Since forcing files are often re-used between experiments it is a best practice to save those intermediate files for re-use between experiments. These logical save-points in workflows are called ‘rustpunten’ in Dutch. It is important to store data in ‘rustpunten’ in standard formats. Working with clearly defined ‘rustpunten’ is a key element in the design of good workflows in general and was instrumental in designing eWaterCycle in particular.
Here we set up some paths to store the forcing files we generate in your own home directory.
To speed up this workshop, we have already created the forcing files in a central location, which we also create pointers to here. If you want to run for a different region, you will have to generate the forcing yourself.
forcing_path_caravan = Path.home() / "forcing" / camelsgb_id / "caravan"
forcing_path_caravan.mkdir(exist_ok=True, parents=True)
prepared_forcing_path_caravan_central = Path("/data/eurocsdms-data/forcing/camelsgb_73010/caravan")
forcing_path_ERA5 = Path.home() / "forcing" / camelsgb_id / "ERA5"
forcing_path_ERA5.mkdir(exist_ok=True)
prepared_forcing_path_ERA5_central = Path("/data/eurocsdms-data/forcing/camelsgb_73010/ERA5")
Generate or load forcing#
There are three options for creating forcing data objects:
generate from climate data such as ERA5 or CMIP. Note that if the directory you specify as destination already contains data this trying this will throw an error!
load forcing data you generated previously by providing the location where it was stored
load forcing data someone else (such as Rolf and Bart) generated previously by providing the location where it was stored
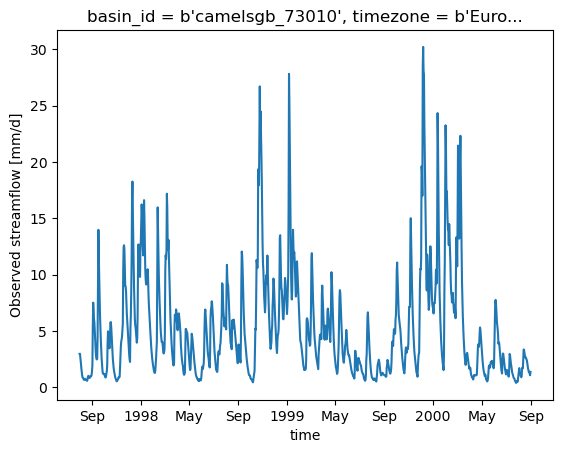
First we will create a caravan forcing object, but as mentioned above, we will only use this for the discharge observations and the shape file of the region. After generating the object we show the fields it contains and plot the discharge data.
The actual forcing object we will use in this example is the ERA5 based data.
For both caravan and ERA5 based forcing, only one of the three options provided below should be used, use comments to select which one you want to use.
# # option one: generate forcing data
# camelsgb_forcing = ewatercycle.forcing.sources['CaravanForcing'].generate(
# start_time=experiment_start_date,
# end_time=experiment_end_date,
# directory=forcing_path_caravan,
# basin_id=camelsgb_id,
# )
# option two: load data that you or someone else generated previously
camelsgb_forcing = ewatercycle.forcing.sources['CaravanForcing'].load(directory=prepared_forcing_path_caravan_central)
print(camelsgb_forcing)
CaravanForcing( start_time='1997-08-01T00:00:00Z', end_time='2000-08-31T00:00:00Z', directory=PosixPath('/data/eurocsdms-data/forcing/camelsgb_73010/caravan'), shape=PosixPath('/data/eurocsdms-data/forcing/camelsgb_73010/caravan/camelsgb_73010.shp'), filenames={ 'tasmax': 'camelsgb_73010_1997-08-01_2000-08-31_tasmax.nc', 'evspsblpot': 'camelsgb_73010_1997-08-01_2000-08-31_evspsblpot.nc', 'Q': 'camelsgb_73010_1997-08-01_2000-08-31_Q.nc', 'tasmin': 'camelsgb_73010_1997-08-01_2000-08-31_tasmin.nc', 'pr': 'camelsgb_73010_1997-08-01_2000-08-31_pr.nc', 'tas': 'camelsgb_73010_1997-08-01_2000-08-31_tas.nc' } )
#quick plot of the discharge data.
ds_forcing = xr.open_dataset(camelsgb_forcing['Q'])
ds_forcing["Q"].plot()
[<matplotlib.lines.Line2D at 0x7fac934d9130>]
# option one: generate forcing:
# ERA5_forcing = ewatercycle.forcing.sources["LumpedMakkinkForcing"].generate(
# dataset="ERA5",
# start_time=experiment_start_date,
# end_time=experiment_end_date,
# shape=camelsgb_forcing.shape,
# )
# option two: load data that you or someone else generated previously
# this is needed because ERA5 forcing data is stored deep in a sub-directory
load_location = prepared_forcing_path_ERA5_central / "work" / "diagnostic" / "script"
ERA5_forcing = ewatercycle.forcing.sources["LumpedMakkinkForcing"].load(directory=load_location)
Load parameters from calibration#
The HBV model contains five “stores” where the water is stored and nine parameters that control the flow between those stores and in and out of the model. We have already calibrated the model for our region of choice and saved the result in a csv file which we load below. If you have changed the region and have calibrated for your region, you need to point to your calibration results here.
#load calibration constants
par_0 = np.loadtxt("/data/eurocsdms-data/calibration/calibration_" + camelsgb_id + ".csv", delimiter = ",")
param_names = ["Imax", "Ce", "Sumax", "Beta", "Pmax", "Tlag", "Kf", "Ks", "FM"]
print(list(zip(param_names, np.round(par_0, decimals=3))))
[ ('Imax', 7.085), ('Ce', 0.837), ('Sumax', 76.373), ('Beta', 1.112), ('Pmax', 0.245), ('Tlag', 7.801), ('Kf', 0.096), ('Ks', 0.003), ('FM', 0.226) ]
For the storages we can specify an array of starting values. If you don’t the model will start ‘empty’ and needs some timesteps to ‘fill up’. Especially for the rootzone storage it helps to not start empty. Note that all units are in mm:
# Si, Su, Sf, Ss, Sp
s_0 = np.array([0, 100, 0, 5, 0])
Setting up the model#
Below we show the core use of eWaterCycle: to users models are objects. We stay as close as possible to the standard BMI functions, but make sure that under the hood eWaterCycle makes everything run. Getting a model to run requires three steps:
creating a model object, an instance of the specific model class. This is provided by the different plugins. At the point of creation, the forcing object that will be used need to be passed to the model:
model = ewatercycle.models.HBV(forcing=ERA5_forcing)
creating a configuration file that contains all the information the model needs to initialize itself. The format of the configuration file is very model specific. For example, the HBV configuration file contains information on:
the location of forcing files
the values of parameters and initial storages
config_file, _ = model.setup(parameters=par_0, initial_storage=s_0)
initializing starts the model container, creates all variables, and basically gets the model primed to start running.
model.initialize(config_file)
Running the model#
The basic loop that runs the model calls the model.update() to have the model progress one timestep and model.get_value() to extract information of interest. More complex experiment can interact with the model using, for example, model.set_value() to change values. In this way
multiple models can interact (including be coupled)
models can be adjusted during runtime to incoming observations (ie. data assimilation)
Effects not covered by the model can be calculated seperatly and included to create ‘what if’ experiments.
and many more applications.
Q_m = []
time = []
while model.time < model.end_time:
model.update()
Q_m.append(model.get_value("Q")[0])
time.append(pd.Timestamp(model.time_as_datetime))
After running the model we need to call model.finalize() to shut everything down, including the container. If we don’t do this, the container will continue to be active, eating up system memory.
model.finalize()
Process results#
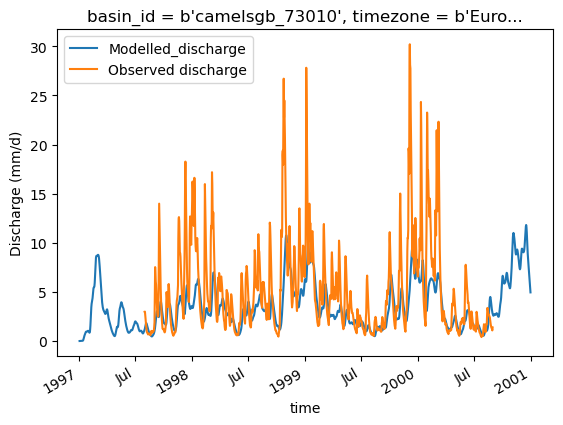
Finally, we use standard python libraries to visualize the results. We put the model output into a pandas Series to make plotting easier.
model_output = pd.Series(data=Q_m, name="Modelled_discharge", index=time)
model_output.plot()
ds_forcing["Q"].plot(label="Observed discharge")
plt.legend()
plt.ylabel("Discharge (mm/d)")
Text(0, 0.5, 'Discharge (mm/d)')
#we want to also be able to use the output of this model run in different analyses. Therefore we save it as a NetCDF file
xr_model_output = model_output.to_xarray()
xr_model_output.attrs['units'] = 'mm/d'
# Save the xarray Dataset to a NetCDF file
xr_model_output.to_netcdf('~/river_discharge_data.nc')